
中到英新闻翻译媲美人类,微软机器翻译新突破
今日,微软研究团队表示,微软和微软亚研创造了首个在质量与准确率上匹配人类水平的中英新闻机器翻译系统。黄学东告诉机器之心,他们采用专业人类标注与盲测评分代替 BLEU 分值而具有更高的准确性,且新系统相比于现存的机器翻译系统有非常大的提升。因此,根据人类盲测评分,微软机器翻译取得了至少和专业翻译人员相媲美的效果。
微软亚洲与美国实验室的研究者称,其中英新闻机器翻译系统在常用的新闻报道测试集 newstest 2017 上达到了人类水平。该测试集由来自业界和学界的团队共同开发,去年秋季在 WMT17 会议上发布。为了保证结果既准确又能达到人类水平,该团队聘请了外部双语评估员,他们对比了微软的结果与两组独立翻译的人类译文。
微软语音、自然语言与机器翻译的技术负责人黄学东称之为自然语言处理最具挑战性任务中的重要里程碑。他对机器之心说:「我们的新系统相比之前的翻译系统有非常大的提升,因此它确实是一个重大突破,是一个历史性的里程碑。」
「机器翻译达到人类水平是我们所有人的梦想,」黄说道,「我们只是没想到这么快就实现了。」
黄学东也领导了最近在对话语音识别任务中达到人类水平的研究组,他认为取得机器翻译任务的这一里程碑尤其令人高兴,因为它可以帮助人们更好地理解彼此。
黄学东说:「消除语言障碍,帮助人们更流畅地交流,这真的非常了不起,非常非常有价值。」
机器翻译是研究者研究了数十年的问题,专家称,很长时间以来人们都认为机器翻译无法达到人类水平。研究者现在仍应该注意该里程碑时间并不意味着机器翻译问题已经被解决。
微软亚洲研究院副院长、自然语言处理组主任周明参与了该项目,称研究团队非常激动能够在该数据集上达到与人类匹配的机器翻译水平。但是他提到,目前仍然存在很多挑战,如还需要在实时新闻报道上对该系统进行测试。
微软机器翻译团队研究经理 Arul Menezes 称,他们团队计划在测试集上证明该系统在中英语言对上可以达到与人类匹配的水平(中英语言对数据较多),此外,测试集还包括大众新闻报道中更常见的词汇。
「考虑到目前数据和可用资源所能达到的最佳案例,我们想找出该系统是否能够实际匹配人类专业译者的水平。」Menezes 称,他也主导了该项目。
Menezes 称研究团队可以将这一技术突破应用于微软的多语商用翻译产品。这将为更准确、自然流畅的跨语言翻译和更复杂或罕见的词汇翻译铺平道路。
对偶学习、推敲、联合训练和一致性正则化
尽管学术和业界的研究者多年来一直在研究机器翻译,但近期使用深度神经网络训练 AI 系统的方法取得了实质性的突破。这些机器翻译系统能够输出更流畅、自然的译文,且比以前的统计机器翻译方法有更广阔的适用范围。
为了在该数据集上训练出能达到人类水平的翻译系统,位于北京、雷德蒙德的三个微软研究团队通力合作,增加了许多其它训练方法帮助系统更加流畅和准确。在许多情况下,这些新方法模拟人类改进翻译工作的过程,一遍遍地迭代直到实现正确结果。
微软亚研首席研究员刘铁岩领导了该项目的机器学习团队,他表示:「我们大部分研究都受到人类工作方式的启发。」
他们使用的一种方法是对偶学习(dual learning)。我们可以把它看作一种核查系统工作的方法:每次他们向系统发送一个中译英的语句,然后再将英译文翻译成中文。这就好像人们想要确保自动翻译结果是准确的,这一方法允许系统从自身的错误中学习。微软研究团队研发的对偶学习也可用于提升其他 AI 任务的结果。
另一种方法称为推敲网络(deliberation network),它与人类经常通读全文来编辑和修改译文的过程非常相似。研究人员会教系统重复翻译相同语句的过程,并逐步润色和提升译文效果。
研究者同样开发了两种新技术以提升其翻译准确率,周明说。一项叫作联合训练(joint training)的技术可用于迭代地提升英中、中英翻译系统。通过这一方法,英中翻译系统把新的英语语句翻译成中文,从而获得新的句对,用于增强中英翻译训练集。相同操作接着再用于中英翻译系统。随着不断收敛,两个系统的表现都获得了提升。
另一项技术是一致性正则化(agreement regularization)。有了它,系统通过从左到右或从右到左的读取即可生成翻译。如果这两个翻译技术生成了相同的翻译,则结果相比没有获得相同翻译更加值得信任。该方法用于鼓励系统生成一致的翻译结果。
周明称他希望这些方法和技术也对其他语言的机器翻译提升有所帮助,并带来翻译领域之外的 AI 突破。
「这些有助于机器翻译的方法和技术也可应用于整个 AI 研究领域」他说。
没有「正确」答案
该研究团队使用的测试集包含了一个在线新闻样本的 2000 个语句,同时该测试集也被专业译者翻译过。
微软在该测试集上进行了多轮评估,每次随机选取数百个译文。为了验证微软的机器翻译水平和人类相当,该公司在该测试集的评估规范之外,还聘请了外部双语语言顾问来对比微软和人类译者的翻译结果。
验证结果的方法也表明训练准确的机器翻译系统的复杂性。在其他任务中,例如语音识别,判断系统的表现是否和人类一样好是很直接的,因为理想结果对于人类和机器来说都是一样的。研究者称其为模式识别任务。
而在翻译任务中存在很多微妙差别。即使两个文笔流畅的人类译者对同一句话的译文也可能略有不同,并且二者都是正确的。这是因为一句话的正确译文并不是唯一的。
「机器翻译相比模式识别任务要复杂得多,」周说。「人们可以使用不同的词来描述同样的东西,你未必能够指出哪一个更好。」
研究者称正是这种复杂性使得机器翻译尤其困难,也正是这一点让它变得如此有趣。
刘说没有人知道机器翻译是否有朝一日能将任何语言文本翻译得足够好,在准确性和抒情性方面都能和人类译者相当。但是,他说,近期的这些研究突破将使他们迈向下一个长期计划,向这个目标和其它伟大的 AI 成就前进,例如在语音转语音翻译中达到人类水平。
「我们可以预测,我们一定能做得越来越好。」刘说。
论文:Achieving Human Parity on Automatic Chinese to English News Translation

摘要:机器翻译近年来发展迅速,现在数百万人使用在线翻译系统和移动 app 进行跨语言沟通。那么我们自然会想到这个问题:机器翻译系统能否接近或达到人类翻译水平。本论文中,我们首次解决了如何定义和准确评估机器翻译是否与人类翻译水平相当的问题。我们介绍了微软的机器翻译系统,并在广泛使用的 WMT 2017 中英新闻翻译任务上对该系统的译文质量进行了评估。评估结果表明我们最新的神经机器翻译系统实现了新的当前最优结果,译文质量与人类专业译者水平相当。我们还发现它显著优于众包业余译者的译文质量。
2 人类翻译水平
直观来看,我们将与人类翻译水平相当定义为:
1. 如果一个具备双语能力的人判断人类输出的译文质量与机器输出的译文质量相当,则机器达到人类水平。
2. 如果机器翻译系统在测试集上的译文质量评分(人工评分)与人类译文得分没有显著差别,则机器达到人类水平。
微软选择了第二个定义来鉴定机器翻译是否达到了人类翻译水平,这相对而言比较公平且比较有实际意义。给定可靠的翻译质量评分指标,基于人类直接测评的方式,我们可以使用成对统计显著性检验来决定机器翻译系统在测试集上是否达到了人类翻译水平。
现有的多种机器翻译评测方法通常基于参考译文,可能会出现偏差,因此微软采用了 WMT17 [6] 使用的直接评估方法作为人工评分方法。为了避免人工评分过程中出现偏差,微软和 IWSLT17 [7] 一样使用了基于来源(source-based)的评价方法。
4 实验
表 1 第一部分展示了基线模型的结果。首先,我们对比了 WMT 2017 最佳结果搜狗系统 [42]。尽管搜狗系统是多个系统的集成,我们这里仍把它作为对照。该表中的其他系统都是单个系统。我们的基线系统 Base 在 1800 万句子上训练。BT 在基线模型的基础上添加了回译数据。
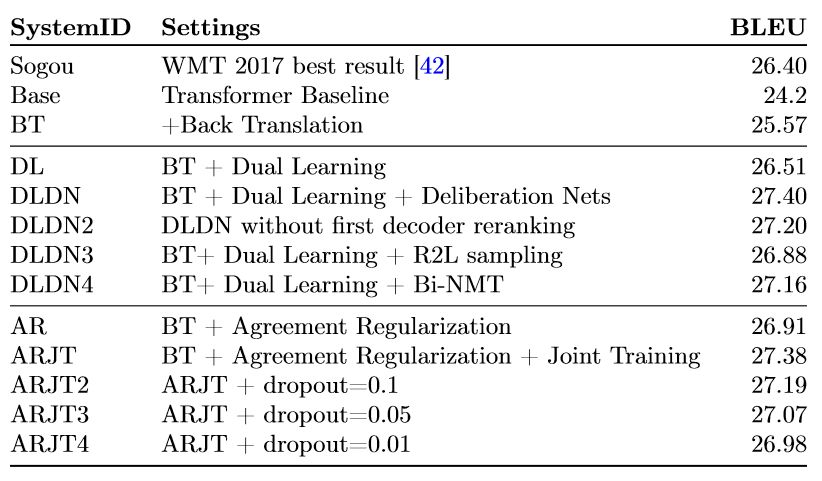
表 1: WMT 2017 中英测试集上的自动评估结果(BLEU 值)。
选择数据的实验结果
Base8K 使用基线数据和回译数据,但是它使用的模型架构较大,处理大型数据集的效果更好。
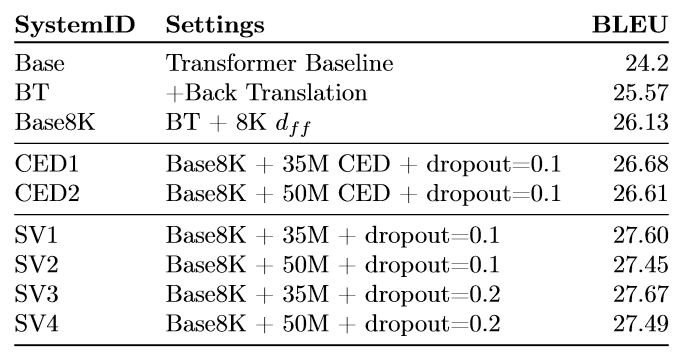
表 2:WMT 2017 中英测试集上的选择数据评估结果。
组合系统的实验结果
如表 3 所示,结合一组异构系统可以互补,实现更好的结果。我们对许多组合系统的配置与特征进行了实验,发现最有帮助的评分特征为 SY SScore、LMScore、R2Lscore、R2LSV 和 E2ZSV。这是非常令人惊奇的,因为组合系统关注于建模相似的特征。这可能是由于这些模型学习互补特征,它们有额外的能力相互补充。

表 3:WMT 2017 中英测试集上的组合系统结果。
5 人类评估结果
表 4 展示了我们的大规模人类评估结果。基于这些结果,我们认为,根据定义 2,我们在新闻领域中英翻译方面已经达到了人类水平,因为我们的系统结果和人类译文无显著差别。
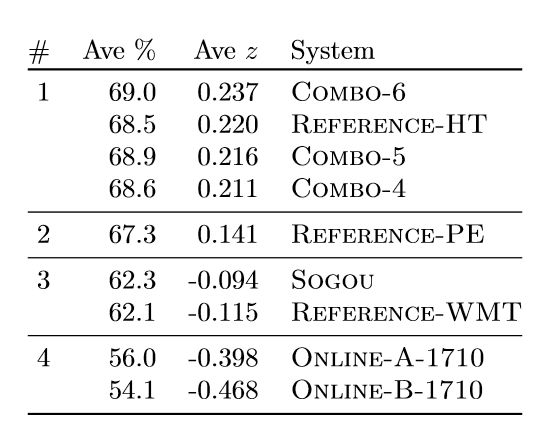
表 4:人类评估结果(每个系统至少有 n≥1827 个评估结果)表明我们的研究系统 Combo-4、Combo-5 和 Combo-6 达到了和人类相当的中英翻译水平(根据定义 2),因为其翻译结果和 Reference-HT(人类翻译)无显著差别。我们所有系统的译文质量都显著超越了 Reference-PE(基于机器翻译输出的译后编辑结果),以及 Reference-WMT(也是人类翻译)。# 表示集群的排名,Ave% 是平均原始分数 r ∈ [0,100],Ave Z 表示标准 z 分数。n≥x 表示我们为该系统收集了至少 x 份评估结果。在表 5g 中表示为 Meta-1。
上表中,根据 p-level(p ≤ 0.05)的 Wilcoxon 秩和检测(和 WMT17 一样),更高层集群的系统显著优于更低集群的系统。相同集群中的系统通过 z 分数进行排序(z 分数即围绕平均值的标准差),z 分数在标注者级别上进行计算,以避免不同标注行为的影响,同时保证质量。
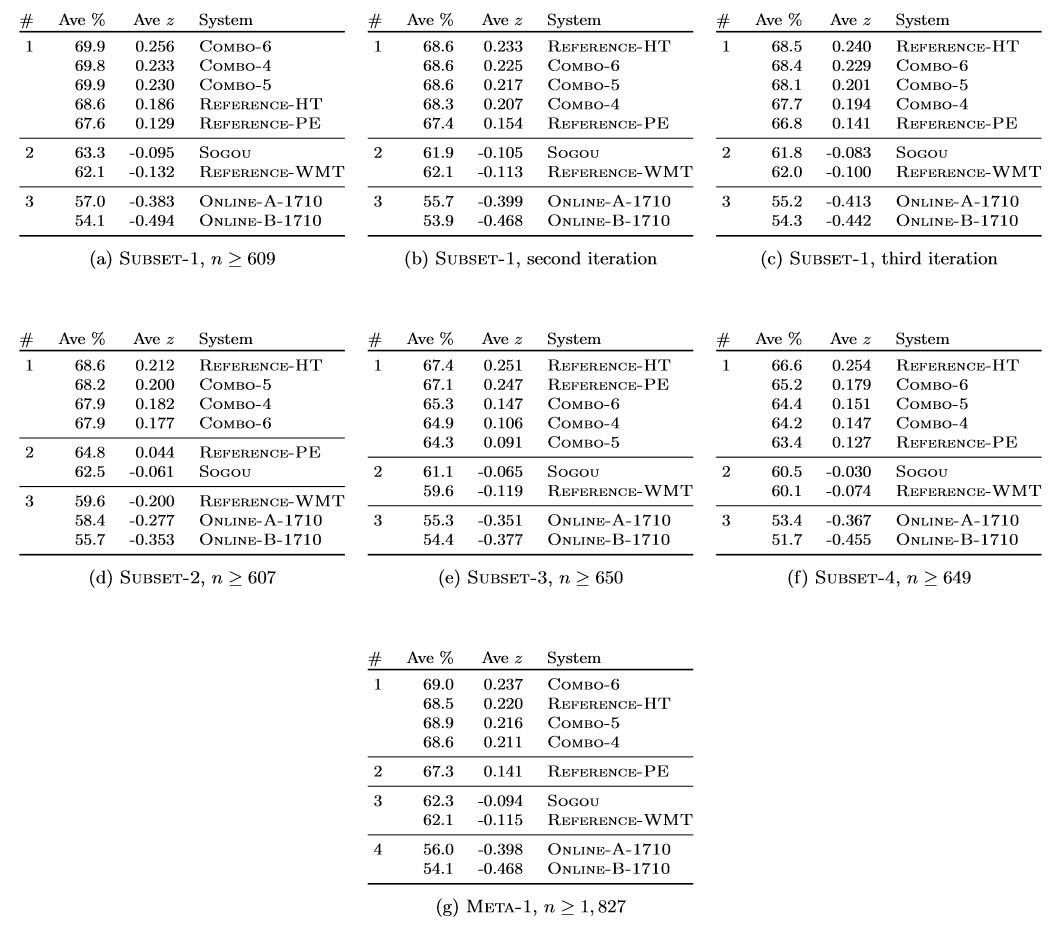
表 5:我们在 Subset-1(5a、5b、5c)上实现三次迭代的完整结果,以及在 Subset2 (5d)、Subset-3 (5e) 和 Subset-4 (5f) 上的评估结果对比。我们还展示了 Meta-1(5g)的组合数据结果,它将 Subset-1 上所有迭代的标注组合在一起。# 表示集群的排名、Ave % 表示平均原始分数,r ∈ [0,100]、Ave z 为标准化的 z 分数。n ≥ x 表示我们为各系统及其评估活动收集了至少 x 份评估结果。所有活动涉及 a = 15 个标注者。根据 p-level(p ≤ 0.05)上的 Wilcoxon 秩和检验,更高层集群中的系统显著地优于低层集群中的所有系统。同一集群中的系统根据 z 分数排序,但同时与质量有紧密联系。
6 人类分析
表 7 展示了标注出的错误的分布,即包含特定错误类别的句子片段所占比例。
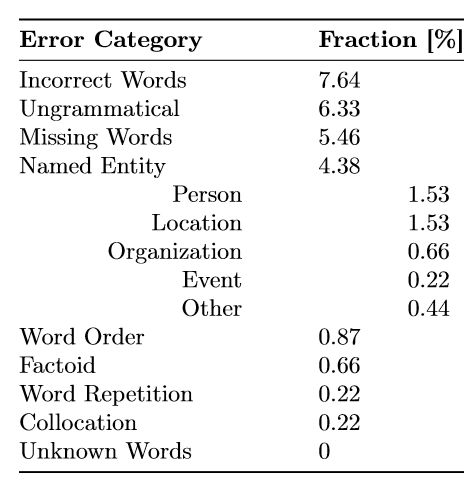
表 7:错误分布,即包含特定错误类别的句子片段所占的比例。
相关文章